

Back in August 2022, Sophos X-Ops published a white paper on multiple attackers – that is, adversaries targeting the same organizations multiple times. One of our key recommendations in that research was to prevent repeated attacks by ‘prioritizing the worst bugs first’: patching critical or high-profile vulnerabilities that could affect users’ specific software stacks. While we think this is still good advice, prioritization is a complex issue. How do you know what the worst bugs are? And how do you actually prioritize remediation, given that resources are more or less the same but the number of published CVEs per year continues to increase, from 18,325 in 2020, to 25,277 in 2022, to 29,065 in 2023? And according to recent research, the median remediation capacity across organizations is 15% of open vulnerabilities in any given month.
A common approach is to prioritize patching by severity (or by risk, a distinction we’ll clarify later) using CVSS scores. FIRST’s Common Vulnerabilities Scoring System has been around for a long time, provides a numerical ranking of vulnerability severity between 0.0 and 10.0, and is not only widely used for prioritization but mandated in some industries and governments, including the Payment Card Industry (PCI) and parts of the US federal government.
As for how it works, it’s deceptively simple. You plug in details about a vulnerability, and out comes a number which tells you whether the bug is Low, Medium, High, or Critical. So far, so straightforward; you weed out the bugs that don’t apply to you, focus on patching the Critical and High vulnerabilities out of what’s left, and either patch the Mediums and Lows afterwards or accept the risk. Everything is on that 0-10 scale, so in theory this is easy to do.
But there’s more nuance to it than that. In this article, the first of a two-part series, we’ll take a look at what goes on under the hood of CVSS, and explain why it isn’t necessarily all that useful for prioritization by itself. In the second part, we’ll discuss some alternative schemes which can provide a more complete picture of risk to inform prioritization.
Before we start, an important note. While we’ll discuss some issues with CVSS in this article, we are very conscious that creating and maintaining a framework of this type is hard work, and to some degree a thankless task. CVSS comes in for a lot of criticism, some pertaining to inherent issues with the concept, and some to the ways in which organizations use the framework. But we should point out that CVSS is not a commercial, paywalled tool. It is made free for organizations to use as they see fit, with the intent of providing a useful and practical guide to vulnerability severity and therefore helping organizations to improve their response to published vulnerabilities. It continues to undergo improvements, often in response to external feedback. Our motivation in writing these articles is not in any way to disparage the CVSS program or its developers and maintainers, but to provide additional context and guidance around CVSS and its uses, specifically with regards to remediation prioritization, and to contribute to a wider discussion around vulnerability management.
CVSS is “a way to capture the principal characteristics of a vulnerability and produce a numerical score reflecting its severity,” according to FIRST. That numerical score, as mentioned earlier, is between 0.0 and 10.0, giving 101 possible values; it can then be turned into a qualitative measure using the following scale:
- None: 0.0
- Low: 0.1 – 3.9
- Medium: 4.0 – 6.9
- High: 7.0 – 8.9
- Critical: 9.0 – 10.0
The system has been around since February 2005, when version 1 was released; v2 came out in June 2007, followed by v3 in June 2015. v3.1, released in June 2019, has some minor amendments from v3, and v4 was published on October 31, 2023. Because CVSS v4 has not yet been widely adopted as of this writing (e.g., the National Vulnerability Database (NVD) and many vendors including Microsoft are still predominantly using v3.1), we will look at both versions in this article.
CVSS is the de facto standard for representing vulnerability severity. It appears on CVE entries in the NVD as well as in various other vulnerability databases and feeds. The idea is that it produces a single, standardized, platform-agnostic score.
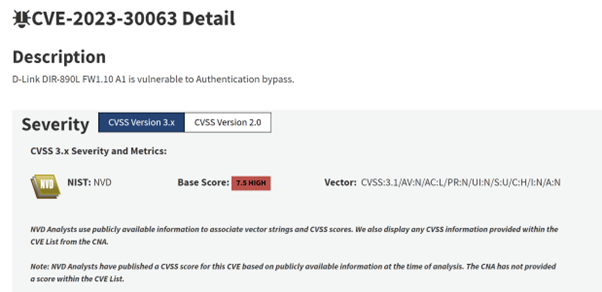
Figure 1: The entry for CVE-2023-30063 on the NVD. Note the v3.1 Base Score (7.5, High) and the vector string, which we’ll cover in more detail shortly. Also note that as of March 2024, the NVD does not incorporate CVSS v4 scores
The figure most providers use is the Base Score, which reflects a vulnerability’s intrinsic properties and its potential impacts. Calculating a score involves assessing a vulnerability via two sub-categories, each with its own vectors which feed into the overall equation.
The first subcategory is Exploitability, which contains the following vectors (possible values are in brackets) in CVSS v4:
- Attack Vector (Network, Adjacent, Local, Physical)
- Attack Complexity (Low, High)
- Attack Requirements (None, Present)
- Privileges Required (None, Low, High)
- User Interaction (None, Passive, Active)
The second category is Impact. Each of the vectors below have the same three possible values (High, Low, and None):
- Vulnerable System Confidentiality
- Subsequent System Confidentiality
- Vulnerable System Integrity
- Subsequent System Integrity
- Vulnerable System Availability
- Subsequent System Availability
So how do we get to an actual number after supplying these values? In v3.1, as shown in FIRST’s CVSS specification document, the metrics (slightly different to the v4 metrics listed above) have an associated numerical value:
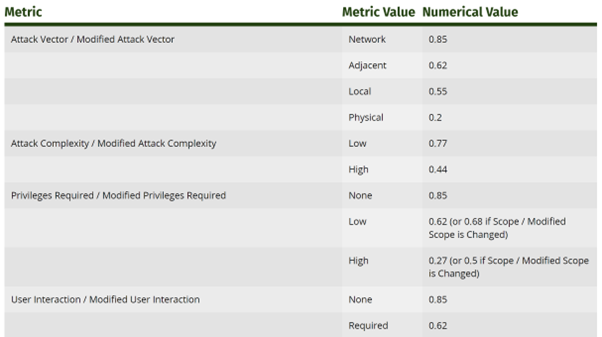
Figure 2: An excerpt from FIRST’s CVSS v3.1 documentation, showing the numerical values of various metrics
To calculate the v3.1 Base score, we first calculate three sub-scores: an Impact Sub-Score (ISS), an Impact Score (which uses the ISS), and an Exploitability Score.
Impact Sub-Score
1 – [(1 – Confidentiality) * (1 – Integrity) * (1 – Availability)]
Impact Score
- If scope is unchanged, 42 * ISS
- If scope is changed, 52 * (ISS – 0.029) – 3.25 * (ISS – 0.02)15
Exploitability Score
8.22 * AttackVector * AttackComplexity * PrivilegesRequired * UserInteraction
Base Score
Assuming the Impact Score is greater than 0:
- If scope is unchanged: (Roundup (Minimum [(Impact + Exploitability), 10])
- If scope is changed: Roundup (Minimum [1.08 * (Impact + Exploitability), 10])
Here, the equation uses two custom functions, Roundup and Minimum. Roundup “returns the smallest number, specified to one decimal place, that is equal to or higher than its input,” and Minimum “returns the smaller of its two arguments.”
Given that CVSS is an open-source specification, we can work through an example of this manually, using the v3.1 vector string for CVE-2023-30063 shown in Figure 1:
CVSS:3.1/AV:N/AC:L/PR:N/UI:N/S:U/C:H/I:N/A:N
We’ll look up the vector results and their associated numerical values, so we know what numbers to plug into the equations:
- Attack Vector = Network = 0.85
- Attack Complexity = Low = 0.77
- Privileges Required = None = 0.85
- User Interaction = None = 0.85
- Scope = Unchanged (no associated value in itself; instead, Scope can modify other vectors)
- Confidentiality = High = 0.56
- Integrity = None = 0
- Availability = None = 0
First, we calculate the ISS:
1 – [(1 – 0.56) * (1 – 0) * (1 – 0] = 0.56
The Scope is unchanged, so for the Impact score we multiply the ISS by 6.42, which gives us 3.595.
The Exploitability score is 8.22 * 0.85 * 0.77 * 0.85 * 0.85, which gives us 3.887.
Finally, we put this all into the Base Score equation, which effectively adds these two scores together, giving us 7.482. To one decimal place this is 7.5, as per the CVSS v3.1 score on NVD, which means this vulnerability is considered to be High severity.
v4 takes a very different approach. Among other changes, the Scope metric has been retired; there is a new Base metric (Attack Requirements); and the User Interaction now has more granular options. But the most radical change is the scoring system. Now, the calculation method no longer relies on ‘magic numbers’ or a formula. Instead, ‘equivalence sets’ of different combinations of values have been ranked by experts, compressed, and put into bins representing scores. When calculating a CVSS v4 score, the vector is computed and the associated score returned, using a lookup table. So, for example, a vector of 202001 has an associated score of 6.4 (Medium).
Regardless of the calculation method, the Base Score isn’t supposed to change over time, since it relies on characteristics inherent to the vulnerability. However, the v4 specification also offers three other metric groups: Threat (the characteristics of a vulnerability that change over time); Environmental (characteristics that are unique to a user’s environment); and Supplemental (additional extrinsic attributes).
The Threat Metric Group includes only one metric (Exploit Maturity); this replaces the Temporal Metric Group from v3.1, which included metrics for Exploit Code Maturity, Remediation Level, and Report Confidence. The Exploit Maturity metric is designed to reflect the likelihood of exploitation, and has four possible values:
- Not Defined
- Attacked
- Proof-of-Concept
- Unreported
Whereas the Threat Metric Group is designed to add additional context to a Base score based on threat intelligence, the Environmental Metric Group is more of a variation of the Base score, allowing an organization to customize the score “depending on the importance of the affected IT asset to a user’s organization.” This metric contains three sub-categories (Confidentiality Requirement, Integrity Requirement, and Availability Requirement), plus the modified Base metrics. The values and definitions are the same as the Base metrics, but the modified metrics allow users to reflect mitigations and configurations which may increase or decrease severity. For example, the default configuration of a software component might not implement authentication, so a vulnerability in that component would have a Base metric of None for the Privileges Required measure. However, an organization might have protected that component with a password in their environment, in which case the Modified Privileges Required would be either Low or High, and the overall Environmental score for that organization would therefore be lower than the Base score.
Finally, the Supplemental Metric Group includes the following optional metrics, which don’t affect the score.
- Automatable
- Recovery
- Safety
- Value Density
- Vulnerability Response Effort
- Provider Urgency
It remains to be seen how widely used the Threat and Supplemental Metric Groups will be in v4. With v3.1, Temporal metrics rarely appear on vulnerability databases and feeds, and Environmental metrics are intended to be used on a per-infrastructure basis, so it’s not clear how widely adopted they are.
However, Base scores are ubiquitous, and at first glance it’s not hard to see why. Even though a lot has changed in v4, the fundamental nature of the outcome – a figure between 0.0 and 10.0, which purportedly reflects a vulnerability’s severity – is the same.
The system has, however, come in for some criticism.
What does a CVSS score mean?
This isn’t a problem inherent to the CVSS specification, but there can be some confusion as to what a CVSS score actually means, and what it should be used for. As Howland points out, the specification for CVSS v2 is clear that the framework’s purpose is risk management:
“Currently, IT management must identify and assess vulnerabilities across many disparate hardware and software platforms. They need to prioritize these vulnerabilities and remediate those that pose the greatest risk. But when there are so many to fix, with each being scored using different scales, how can IT managers convert this mountain of vulnerability data into actionable information? The Common Vulnerability Scoring System (CVSS) is an open framework that addresses this issue.”
The word ‘risk’ appears 21 times in the v2 specification; ‘severity’ only three. By the v4 specification, these numbers have effectively reversed; ‘risk’ appears three times, and ‘severity’ 41 times. The first sentence of the v4 specification states that the purpose of the framework is “communicating the characteristics and severity of software vulnerabilities.” So, at some point, the stated purpose of CVSS has changed, from a measure of risk to a measure of severity.
That’s not a ‘gotcha’ in any way; the authors may have simply decided to clarify exactly what CVSS is for, to prevent or address misunderstandings. The real issue here doesn’t lie in the framework itself, but in the way it is sometimes implemented. Despite the clarifications in recent specifications, CVSS scores may still sometimes be (mis)used as a measure of risk (i.e., “the combination of the probability of an event and its consequences,” or, as per the oft-cited formula, Threat * Vulnerability * Consequence), but they don’t actually measure risk at all. They measure one aspect of risk, in assuming that an attacker “has already located and identified the vulnerability,” and in assessing the characteristics and potential impact of that vulnerability if an exploit is developed, and if that exploit is effective, and if the reasonable worst-case scenario occurs as a result.
A CVSS score can be a piece of the puzzle, but by no means the completed jigsaw. While it may be nice to have a single number on which to base decisions, risk is a far more complex game.
But I can still use it for prioritization, right?
Yes and no. Despite the increasing numbers of published CVEs (and it’s worth pointing out that not all vulnerabilities receive CVE IDs, so that’s not a completed jigsaw either), only a small fraction – between 2% and 5% – are ever detected as being exploited in-the-wild, according to research. So, if a vulnerability intelligence feed tells you that 2,000 CVEs have been published this month, and 1,000 of them affect assets in your organization, only around 20-50 of those will likely ever be exploited (that we’ll know about).
That’s the good news. But, leaving aside any exploitation that occurs before a CVE’s publication, we don’t know which CVEs threat actors will exploit in the future, or when – so how can we know which vulnerabilities to patch first? One might assume that threat actors use a similar thought process to CVSS, albeit less formalized, to develop, sell, and use exploits: emphasizing high-impact vulnerabilities with low complexity. In which case, prioritizing high CVSS scores for remediation makes perfect sense.
But researchers have shown that CVSS (at least, up to v3) is an unreliable predictor of exploitability. Back in 2014, researchers at the University of Trento claimed that “fixing a vulnerability just because it was assigned a high CVSS score is equivalent to randomly picking vulnerabilities to fix,” based on an analysis of publicly available data on vulnerabilities and exploits. More recently (March 2023), Howland’s research on CVSS shows that bugs with a CVSS v3 score of 7 are the most likely to be weaponized, in a sample of over 28,000 vulnerabilities. Vulnerabilities with scores of 5 were more likely to be weaponized than those with scores of 6, and 10-rated vulnerabilities – Critical flaws – were less likely to have exploits developed for them than vulnerabilities ranked as 9 or 8.
In other words, there does not appear to be a correlation between CVSS score and the likelihood of exploitation, and, according to Howland, that’s still the case even if we weight relevant vectors – like Attack Complexity or Attack Vector – more heavily (although it remains to be seen if this will still hold true with CVSS v4).
This is a counterintuitive finding. As the authors of the Exploit Prediction Scoring System (EPSS) point out (more on EPSS in our follow-up article), after plotting CVSS scores against EPSS scores and finding less correlation than expected:
“this…provides suggestive evidence that attackers are not only targeting vulnerabilities that produce the greatest impact, or are necessarily easier to exploit (such as for example, an unauthenticated remote code execution).”
There are various reasons why the assumption that attackers are most interested in exploiting exploits for severe, low-effort vulnerabilities doesn’t hold up. As with risk, the criminal ecosystem can’t be reduced to a single facet. Other factors which might affect the likelihood of weaponization include the install base of the affected product; prioritizing certain impacts or product families over others; differences by crime type and motivation; geography, and so on. This is a complex, and separate, discussion, and out of scope for this article – but, as Jacques Chester argues in a thorough and thought-provoking blog post on CVSS, the main takeaway is: “Attackers do not appear to use CVSSv3.1 to prioritize their efforts. Why should defenders?” Note, however, that Chester doesn’t go so far as to argue that CVSS should not be used at all. But it probably shouldn’t be the sole factor in prioritization.
Reproducibility
One of the litmus tests for a scoring framework is that, given the same information, two people should be able to work through the process and come out with approximately the same score. In a field as complex as vulnerability management, where subjectivity, interpretation, and technical understanding often come into play, we might reasonably expect a degree of deviation – but a 2018 study showed significant discrepancies in assessing the severity of vulnerabilities using CVSS metrics, even among security professionals, which could result in a vulnerability being eventually classified as High by one analyst and Critical or Medium by another.
However, as FIRST points out in its specification document, its intention is that CVSS Base scores should be calculated by vendors or vulnerability analysts. In the real world, Base scores typically appear on public feeds or databases which organizations then ingest – they’re not intended to be recalculated by lots of individual analysts. That’s reassuring, although the fact that experienced security professionals made, in some cases at least, quite different assessments could be a cause for concern. It’s not clear whether that was a consequence of ambiguity in CVSS definitions, or a lack of CVSS scoring experience among the study’s participants, or a wider issue relating to divergent understanding of security concepts, or some or all of the above. Further research is probably needed on this point, and on the extent to which this issue still applies in 2024, and to CVSS v4.
Harm
CVSS v3.1’s impact metrics are limited to those associated with traditional vulnerabilities in traditional environments: the familiar CIA triad. What v3.1 does not take into account are more recent developments in security, where attacks against systems, devices, and infrastructure can cause significant physical harm to people and property.
However, v4 does address this issue. It includes a dedicated Safety metric, with the following possible values:
- Not Defined
- Present
- Negligible
With the latter two values, the framework uses the IEC 61508 standard definitions of “negligible” (minor injuries at worst), “marginal” (major injuries to one or more persons), “critical” (loss of a single life), or “catastrophic” (multiple loss of life). The Safety metric can also be applied to the modified Base metrics within the Environmental Metric Group, for the Subsequent System Impact set.
Context is everything
CVSS does its best to keep everything as simple as possible, which can sometimes mean reducing complexity. Take v4’s Attack Complexity, for example; the only two possible values are Low and High.
Low: “The attacker must take no measurable action to exploit the vulnerability. The attack requires no target-specific circumvention to exploit the vulnerability. An attacker can expect repeatable success against the vulnerable system.”
High: “The successful attack depends on the evasion or circumvention of security-enhancing techniques in place that would otherwise hinder the attack […].”
Some threat actors, vulnerability analysts, and vendors would likely disagree with the view that a vulnerability is either of ‘low’ or ‘high’ complexity. However, members of the FIRST Special Interest Group (SIG) claim that this has been addressed in v4 with the new Attack Requirements metric, which adds some granularity to the mix by capturing whether exploitation requires certain conditions.
User Interaction is another example. While the possible values for this metric are more granular in v4 than v3.1 (which has only None or Required), the distinction between Passive (limited and involuntary interaction) and Active (specific and conscious interaction) arguably fails to reflect the wide range of social engineering which occurs in the real world, not to mention the complexity added by security controls. For instance, persuading a user to open a document (or just view it in the Preview Pane) is in most cases easier than persuading them to open a document, then disable Protected View, then ignore a security warning.
In fairness, CVSS must walk a line between being overly granular (i.e., including so many possible values and variables that it would take an inordinate amount of time to calculate scores) and overly simplistic. Making the CVSS model more granular would complicate what’s intended to be a quick, practical, one-size-fits-all guide to severity. That being said, it’s still the case that important nuance may be missed – and the vulnerability landscape is, by nature, often a nuanced one.
Some of the definitions in both the v3.1 and v4 specifications may also be confusing to some users. For instance, consider the following, which is provided as a possible scenario under the Attack Vector (Local) definition:
“the attacker exploits the vulnerability by accessing the target system locally (e.g., keyboard, console), or through terminal emulation (e.g., SSH)” [emphasis added; in the v3.1 specification, this reads “or remotely (e.g., SSH)”]
Note that the use of SSH here appears to be distinct from accessing a host on a local network via SSH, as per the Adjacent definition:
“This can mean an attack must be launched from the same shared proximity (e.g., Bluetooth, NFC, or IEEE 802.11) or logical (e.g., local IP subnet) network, or from within a secure or otherwise limited administrative domain…” [emphasis added]
While the specification does make a distinction between a vulnerable component being “bound to the network stack” (Network) or not (Local), this could be counterintuitive or confusing to some users, either when calculating CVSS scores or attempting to interpret a vector string. That’s not to say these definitions are incorrect, only that they might be opaque and unintuitive to some users.
Finally, Howland provides a real-world case study of, in their view, CVSS scores not taking context into account. CVE-2014-3566 (the POODLE vulnerability) has a CVSS v3 score of 3.4 (Low). But it affected almost a million websites at the time of disclosure, caused a significant amount of alarm, and impacted different organizations in different ways – which, Howland argues, CVSS does not take into account. There’s also a separate context-related question – out of scope for this series – on whether media coverage and hype about a vulnerability disproportionately influence prioritization. Conversely, some researchers have argued that vulnerability rankings can be overly high because they don’t always take context into account, when the real-world risk is actually relatively low.
‘We’re just ordinally people…’
In v3.1, CVSS sometimes uses ordinal data as input into equations. Ordinal data is data on a ranked scale, with no known distance between items (e.g., None, Low, High), and, as researchers from Carnegie Mellon University point out, it does not make sense to add or multiply ordinal data items. If, for instance, you’re completing a survey where the responses are on a Likert scale, it’s meaningless to multiply or add those responses. To give a non-CVSS example, if you answer Happy [4.0] to a question about your salary, and Somewhat Happy [2.5] to a question about your work-life balance, you can’t multiply those together and conclude that the overall survey result = 10.0 [‘Very happy with my job’].
The use of ordinal data also means that CVSS scores shouldn’t be averaged. If an athlete wins a gold medal in one event, for example, and a bronze medal in another, it doesn’t make sense to say that on average they won silver.
In v3.1, it’s also not clear how the metrics’ hardcoded numerical values were chosen, which may be one of the reasons for FIRST opting to eschew a formula in v4. Instead, v4’s scoring system relies on grouping and ranking possible combinations of values, calculating a vector, and using a lookup function to assign a score. So, instead of a formula, experts selected by FIRST have determined the severity of different combinations of vectors during a consultation period. On the face of it, this seems like a reasonable approach, as it negates the issue of a formula altogether.
A black box?
While the specification, equations, and definitions for v3.1 and v4 are publicly available, some researchers have argued that CVSS suffers from a lack of transparency. In v4, for example, rather than plugging numbers into a formula, analysts can now look up a vector using a predetermined list. However, it’s not clear how these experts were selected, how they compared “vectors representing each equivalence set,” or how the “expert comparison data” was used “to calculate the order of vectors from least severe to most severe.” To our knowledge, this information has not been made public. As we’ll see in Part 2 of this series, this issue is not unique to CVSS.
As with anything in security, any results produced by a system in which the underlying mechanics are not fully known or understood should be treated with a degree of skepticism commensurate with the importance and nature of the purpose for which they’re used – and with the level of associated risk if those results should prove to be wrong or misleading.
Capping it off
Finally, it may be worth wondering why CVSS scores are between 0 and 10 at all. The obvious answer is that this is a simple scale which is easy to understand, but it’s also arbitrary, especially since the inputs to the equations are qualitative and CVSS is not a probability measure. In v3.1, the Minimum function ensures that scores are capped at 10 (without it, it’s possible for a Base score to reach 10.73, at least by our calculations) – and in v4, the vectoring mechanism caps scores at 10 by design, because it’s the highest ‘bin.’
But is there a maximum extent to which a vulnerability can be severe? Are all vulnerabilities which score 10.0 equally bad? Likely this choice was made for human readability – but is it at the cost of an accurate and realistic representation of severity?
A quick, if imperfect, thought experiment: Imagine a scoring system that claims to measure the severity of biological viruses. The scores can tell you about the possible impact a virus might have on people, perhaps even something about the potential threat of the virus based on some of its characteristics (e.g., an airborne virus is likely to be a more widespread threat than a virus that can only be transmitted via ingestion or physical contact, albeit not necessarily a more severe one).
After inputting information about the virus into an equation, the system generates a very easy-to-understand numerical score between 0 and 10. Parts of the healthcare sector use these scores to prioritize their responses to viruses, and some of the general public rely on them as an indicator of risk – even though that’s not what the system’s developers advise.
But what the scores can’t tell you is how a virus will impact you personally, based on your age, health, immune system efficiency, co-morbidities, immunity via previous infection, and so on. They can’t tell you how likely you are to get infected, or how long it will take you to recover. They don’t consider all of the viruses’ properties (replication rate and ability to mutate, for instance, or geographic distribution of reservoirs and infections) or take wider context into account, such as whether there are vaccines or preventative measures available. As a result, some of the scores seem to make sense (HIV ranks higher than a common rhinovirus, for example), but others don’t (poliovirus scores highly because of its possible impacts, despite being virtually eradicated in most of the world). And independent empirical research has shown that the system’s scores are not helpful in predicting morbidity rates.
So, should you rely solely on this system for conducting personal risk assessments – say, when deciding to attend a party, or go on holiday, or visit someone in hospital? Should the medical community rely on it to prioritize clinical research and epidemiological efforts?
Intuitively, most people would likely have some doubts; it’s clear that the system has some flaws. However, it’s certainly not redundant. It’s helpful for categorization, and for highlighting possible threats based on a virus’s intrinsic properties, because its scores tell you something about the potential consequences of infection. It’s useful, for example, to know that rabies is inherently more severe than chickenpox, even if you’re unlikely to contract rabies on your next night out. You could certainly take this system’s scores into account when conducting a risk assessment, in conjunction with other information. But you’d also want more information.
And, in fairness, FIRST makes this point in its FAQ document for v4. In discussing alternative scoring systems, it notes that they “can be used in concert to better assess, predict, and make informed decisions on vulnerability response priority.” In the next article, we’ll discuss some of these other systems.









